1. Introduction / Objectif
Dans ce projet, l’objectif est d’extraire les informations relatives aux 250 films les mieux notés sur IMDb à l’aide de Python et de bibliothèques spécialisées en web scraping. L’extraction est réalisée dans un cadre éducatif et dans le respect des conditions d’utilisation d’IMDb.
Note : Les données utilisées proviennent d’IMDb et ont été exploitées exclusivement dans un cadre éducatif. Le script complet n’est pas publié ici pour respecter les conditions d’utilisation. Contactez-moi si vous souhaitez discuter du code.
2. Environnement et bibliothèques utilisées
- Requests : envoyer des requêtes HTTP.
- BeautifulSoup (bs4) : parser le HTML et extraire les données.
- Pandas : structurer et manipuler les données.
3. Envoi de la requête HTTP
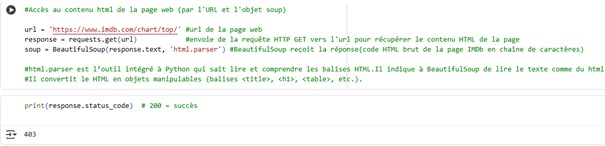
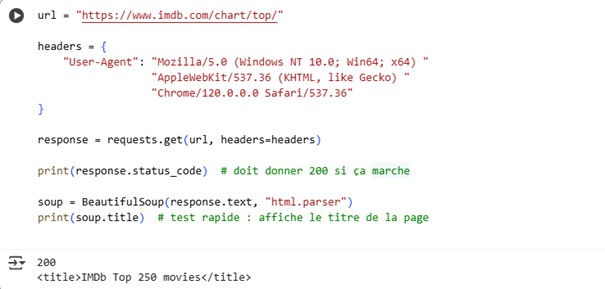
IMDb bloque souvent les requêtes sans User-Agent (erreur 403). La solution consiste à ajouter un en-tête User-Agent pour simuler un navigateur.
4. Navigation dans le HTML
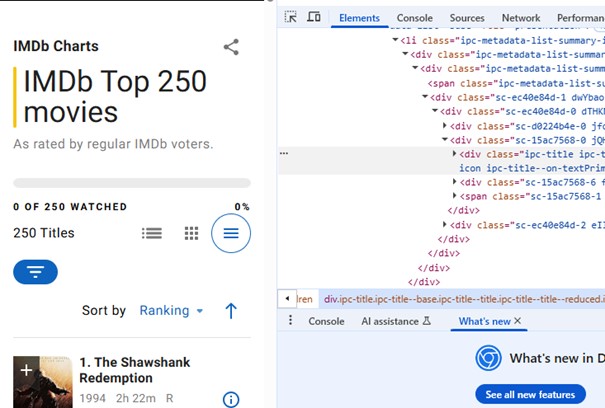
Avant d’extraire les données, inspectez la structure HTML de la page (outil Inspecter). Identifiez les balises et classes contenant les titres, notes et liens.
5. Extraction avec BeautifulSoup
Exemples d’approche avec BeautifulSoup :
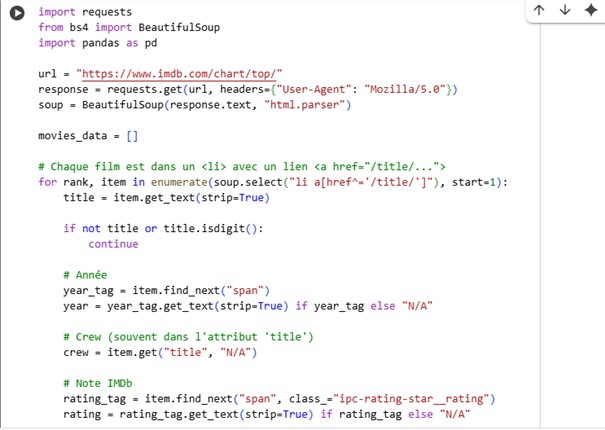
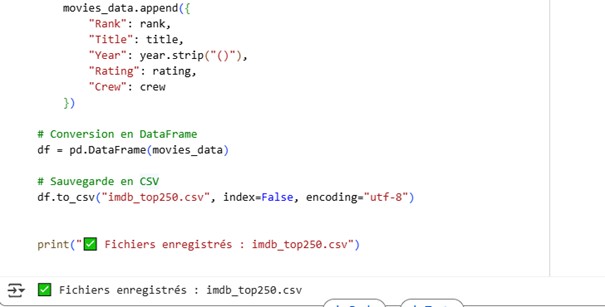

6. Structuration des données
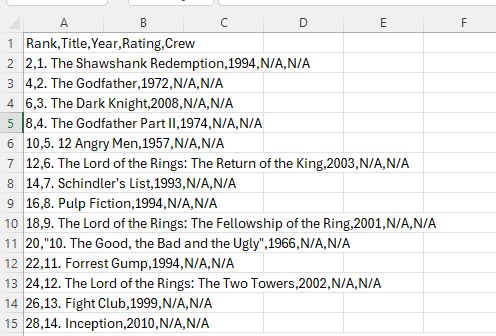
Les données extraites sont stockées dans un DataFrame Pandas pour faciliter l’analyse et la vérification.
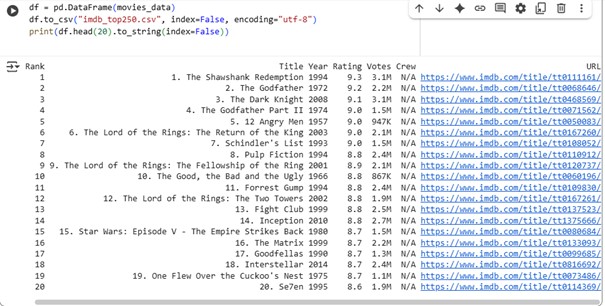
Le script complet n’est pas publié ici pour respecter les conditions d’utilisation d’IMDb. Seule une version simplifiée illustre la méthodologie.
7. Exportation des données (optionnel)
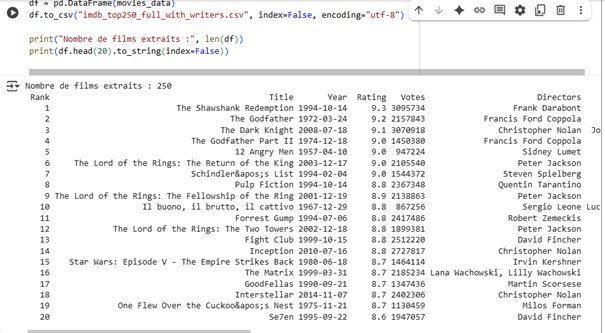
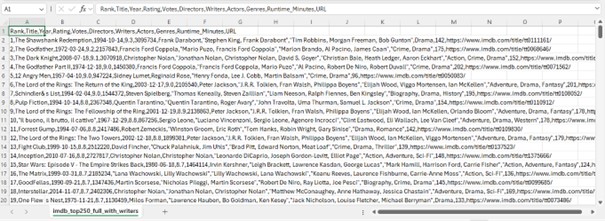
Pour réutiliser les données, exportez-les en CSV avec df.to_csv('imdb_top250.csv', encoding='utf-8', index=False)
8. Conclusion
L’extraction des 250 films les mieux notés d’IMDb a été réalisée avec succès. Les données sont prêtes pour une analyse exploratoire et une visualisation statistique.
Points clés à retenir
- Classement IMDb : Le rang correspond à la position officielle attribuée à chaque film dans le classement Top 250 d’IMDb. Il s’agit d’un indicateur de popularité et de reconnaissance établi à partir des évaluations des utilisateurs.
- Encodage UTF-8 : L’exportation des données s’effectue en utilisant l’encodage UTF-8, garantissant une compatibilité optimale avec les caractères spéciaux et facilitant l’interopérabilité lors du traitement ou du partage des fichiers.
- Maintenance : Étant donné que la structure interne du site IMDb peut évoluer au fil du temps, le code de collecte doit être maintenu et ajusté régulièrement afin d’assurer la continuité et la fiabilité de l’extraction.
- Chargement partiel : Le site IMDb met en œuvre un mécanisme de chargement dynamique qui n’expose qu’une portion limitée du contenu dans le code HTML statique initial. Par conséquent, l’utilisation de bibliothèques telles que BeautifulSoup ne permet d’extraire que les premiers éléments disponibles. Il est donc nécessaire de compléter l’analyse par une méthode adaptée au contenu généré dynamiquement, afin de garantir une récupération exhaustive des données.